
Multi-user Gaze Tracking via Dynamic Image Mapping in 360 Immersive 3D Visualization Systems
Lingyan Ruan, Bin Chen, Chi-Hang Chow, Hiu-Lok Chung, Pok-Yin Victor Leung, Miuling Lam
ACM Special Interest Group on Computer Graphics and Interactive Techniques ( SIGGRPAH Asia Technical Communication 2025)
ABSTRACT: Immersive panoramic 3D visualization systems enhance presence, enabling rich educational, cultural, and collaborative experiences. While gaze offers significant potential as a natural, hands-free interaction modality in such environments, existing solutions often depend on fixed camera setups, fiducial markers, or controller-based navigation, which limit user mobility, reduce gaze estimation accuracy, and introduce visual or physical distractions. We present a real-time, multi-user gaze-driven interaction system for panoramic 3D visualization. The system features a customized unit integrating binocular eye tracking, active stereoscopic glasses, and a scene camera, paired with a portable Android device. The scene camera enables precise gaze mapping onto panoramic 3D content through feature-based alignment with the 360° footage, while the Android device handles real-time gaze estimation and synchronization to ensure low-latency interaction. This approach delivers accurate, responsive gaze mapping for multiple freely moving users without the need for additional tracking infrastructure. Two interactive museum applications demonstrate the system’s capability to support fluid, collaborative, and unobtrusive gaze-based interaction in dynamic cultural and educational installations.


Parameter-Free Neural Lens Blur Rendering for High-Fidelity Composites
Lingyan Ruan, Bin Chen, Taehyun Rhee
IEEE International Symposium on Mixed and Augmented Reality ( ISMAR 2025)
ABSTRACT: Consistent and natural camera lens blur is important for seamlessly blending 3D virtual objects into photographed real-scenes. Since lens blur typically varies with scene depth, the placement of virtual objects and their corresponding blur levels significantly affect the visual fidelity of mixed reality compositions. Existing pipelines of- ten rely on camera parameters (e.g., focal length, focus distance, aperture size) and scene depth to compute the circle of confusion (CoC) for realistic lens blur rendering. However, such informa- tion is often unavailable to ordinary users, limiting the accessibility and generalizability of these methods. In this work, we propose a novel compositing approach that directly estimates the CoC map from RGB images, bypassing the need for scene depth or camera metadata. The CoC values for virtual objects are inferred through a linear relationship between its signed CoC map and depth, and realistic lens blur is rendered using a neural reblurring network. Our method provides flexible and practical solution for real-world applications. Experimental results demonstrate that our method achieves high-fidelity compositing with realistic defocus effects, outperforming state-of-the-art techniques in both qualitative and quantitative evaluations.
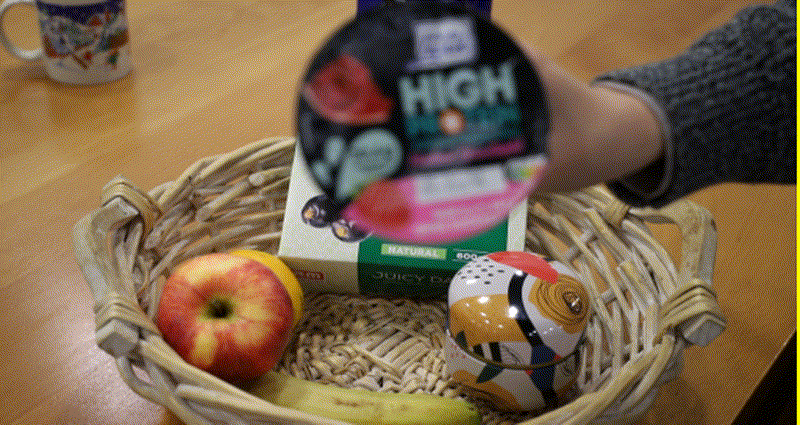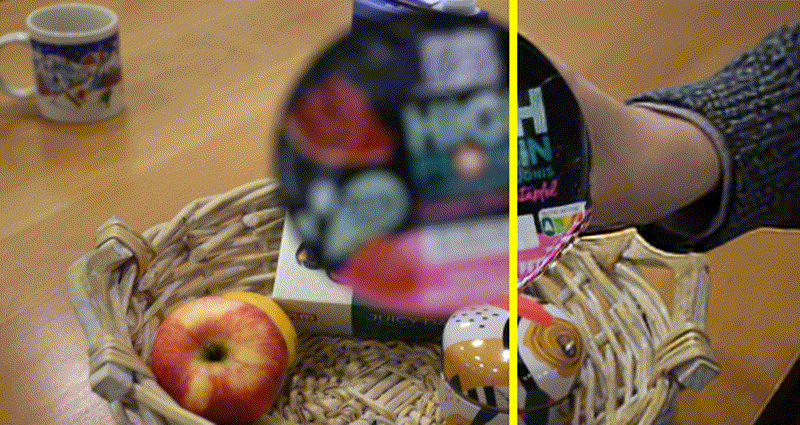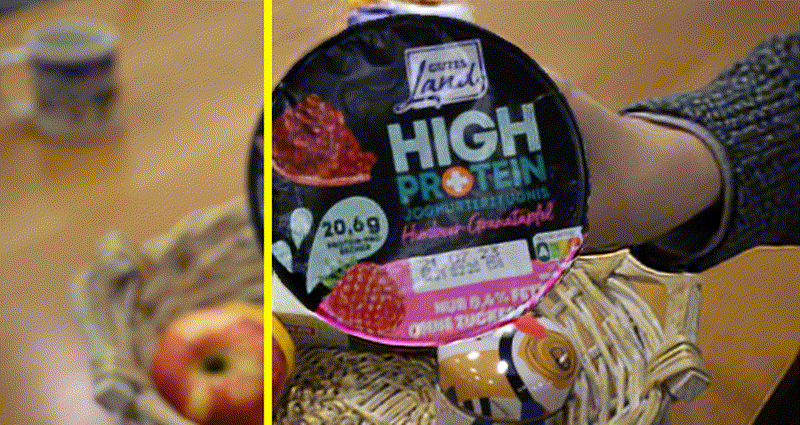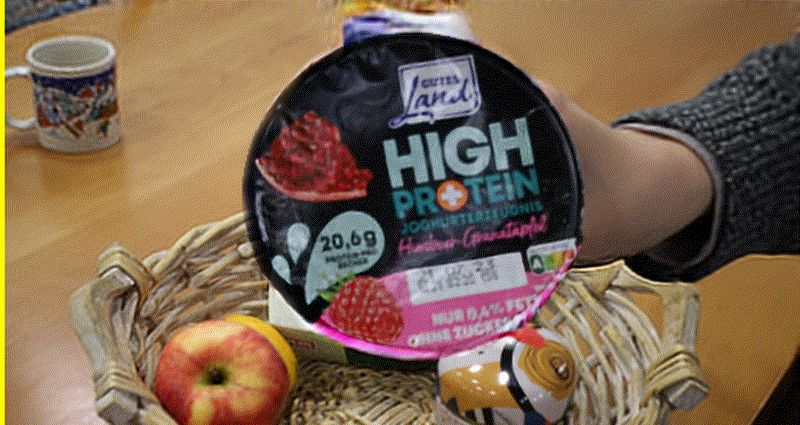

Self-Supervised Video Defocus Deblurring with Atlas Learning
Lingyan Ruan, Martin Bálint, Mojtaba Bemana, Krzysztof Wolski, Hans-peter Seidel, Karol Myszkowski, Bin Chen
ACM Special Interest Group on Computer Graphics and Interactive Techniques (SIGGRAPH 2024)
ABSTRACT: Misfocus is ubiquitous for almost all video producers, degrading video quality and often causing expensive delays and reshoots. Current autofocus (AF) systems are vulnerable to sudden disturbances such as subject movement or lighting changes commonly present in real-world and on-set conditions. Single image defocus deblurring methods are temporally unstable when applied to videos and cannot recover details obscured by temporally varying defocus blur. In this paper, we present an end-to-end solution that allows users to correct misfocus during post-processing. Our method generates and parameterizes defocused videos into sharp layered neural atlases and propagates consistent focus tracking back to the video frames. We introduce a novel differentiable disk blur layer for more accurate point spread function (PSF) simulation, coupled with a circle of confusion (COC) map estimation module with knowledge transferred from the current single image defocus deblurring (SIDD) networks. Our pipeline offers consistent, sharp video reconstruction and effective subject-focus correction and tracking directly on the generated atlases. Furthermore, by adopting our approach, we achieve comparable results to the state-of-the-art optical flow estimation approach from defocus videos.


Learning to Deblur using Light Field Generated and Real Defocus Images
Lingyan Ruan, Bin Chen, Jizhou Li, Miuling Lam
IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR 2022)
[Oral, Best Paper Finalist, Top 0.4%]
ABSTRACT: Defocus deblurring is a challenging task due to the spatially varying nature of defocus blur. While deep learning approach shows great promise in solving image restoration problems, defocus deblurring demands accurate training data that consists of all-in-focus and defocus image pairs, which is difficult to collect. Naive two-shot capturing cannot achieve pixel-wise correspondence between the defocused and all-in-focus image pairs. Synthetic aperture of light fields is suggested to be a more reliable way to generate accurate image pairs. However, the defocus blur generated from light field data is different from that of the images captured with a traditional digital camera. In this paper, we propose a novel deep defocus deblurring network that leverages the strength and overcomes the shortcoming of light fields. We first train the network on a light fieldgenerated dataset for its highly accurate image correspondence. Then, we fine-tune the network using feature loss on another dataset collected by the two-shot method to alleviate the differences between the defocus blur exists in the two domains. This strategy is proved to be highly effective and able to achieve the state-of-the-art performance both quantitatively and qualitatively on multiple test sets. Extensive ablation studies have been conducted to analyze the effect of each network module to the final performance.


Scalable Pattern Formation of Skeletal Myotubes by Synergizing Microtopographic Cues and Chiral Nematics of Cells
Siying Wu*, Lingyan Ruan*, Jianpeng Wu, Minghui Wu, Lok Ting Chu, Hoi Kwan Kwong, Miu Ling Lam, Ting-Hsuan Chen (*equal contribution)
Journal of Biofabrication 2023
ABSTRACT: Topographical cues have been widely used to facilitate cell fusion in skeletal muscle formation. However, an unexpected yet consistent chiral orientation of myotubes deviating from the groove boundaries is commonly observed but has long been unattended. In this study, we report a method to guide the formation of skeletal myotubes into scalable and controlled patterns. By inducing C2C12 myoblasts onto grooved patterns with different widths (from 0.4 to 200μm), we observed an enhanced chiral orientation of cells developing on wide grooves (50 and 100μm width) since the first day of induction. Active chiral nematics of cells involving cell migration and chiral rotation of the cell nucleus subsequently led to a unified chiral orientation of the myotubes. Importantly, these chiral myotubes were formed with enhanced length, diameter, and contractility on wide grooves. Treatment of latrunculin A (Lat A) suppressed the chiral rotation and migration of cells as well as the myotube formation, suggesting the essence of chiral nematics of cells for myogenesis. Finally, by arranging wide grooved/striped patterns with corresponding compensation angles to synergize microtopographic cues and chiral nematics of cells, intricate and scalable patterns of myotubes were formed, providing a strategy for engineering skeletal muscle tissue formation.


AIFNet: All-in-Focus Image Restoration Network Using a Light Field-Based Dataset
Lingyan Ruan, Bin Chen, Jizhou Li, Miuling Lam
IEEE Transactions on Computing Imaging (TCI 2021)
ABSTRACT: Defocus blur often degrades the performance of image understanding, such as object recognition and image segmentation. Restoring an all-in-focus image from its defocused version is highly beneficial to visual information processing and many photographic applications, despite being a severely ill-posed problem. We propose a novel convolutional neural network architecture AIFNet for removing spatially-varying defocus blur from a single defocused image. We leverage light field synthetic aperture and refocusing techniques to generate a large set of realistic defocused and all-in-focus image pairs depicting a variety of natural scenes for network training. AIFNet consists of three modules: defocus map estimation, deblurring and domain adaptation. The effects and performance of various network components are extensively evaluated. We also compare our method with existing solutions using several publicly available datasets. Quantitative and qualitative evaluations demonstrate that AIFNet shows the state-of-the-art performance.


Light Field Display with Ellipsoidal Mirror Array and Single Projector
Bin Chen, Lingyan Ruan, Miuling Lam
Optics Express 2019
ABSTRACT: We present a method to create light field display using a single projector and an array of plane mirrors. Mirrors can reproduce densely arranged virtual projectors regardless of the physical size of the real projector, thus producing a light field display of competitive ray density. We propose an ellipsoidal geometric framework and a design pipeline, and use parametric modelling technique to automatically generate the display configurations satisfying target design parameters. Three units of mirror array light field display systems have been implemented to evaluate the proposed methodologies. More importantly, we have experimentally verified that the high-density light field produced by our method can naturally evoke accommodation of the eyes, thereby reducing the vergence-accommodation conflict. The mirror array approach allows flexible trading between the spatial and angular resolutions for accommodating different applications, thus providing a practical solution to realize projection-based light field display.

LaKDNet: Revisiting Image Deblurring with an Efficient ConvNet
Lingyan Ruan, Mojtaba Bemana, Hans-peter Seidel, Karol Myszkowski, Bin Chen
Technical Report, 2023
ABSTRACT: Image deblurring aims to recover the latent sharp image from its blurry counterpart and has a wide range of applications in computer vision. The Convolution Neural Networks (CNNs) have performed well in this domain for many years, and until recently an alternative network architecture, namely Transformer, has demonstrated even stronger performance. One can attribute its superiority to the multi-head self-attention (MHSA) mechanism, which offers a larger receptive field and better input content adaptability than CNNs. However, as MHSA demands high computational costs that grow quadratically with respect to the input resolution, it becomes impractical for high-resolution image deblurring tasks. In this work, we propose a unified lightweight CNN network that features a large effective receptive field (ERF) and demonstrates comparable or even better performance than Transformers while bearing less computational costs. Our key design is an efficient CNN block dubbed LaKD, equipped with a large kernel depth-wise convolution and spatial-channel mixing structure, attaining comparable or larger ERF than Transformers but with a smaller parameter scale. Specifically, we achieve +0.17dB / +0.43dB PSNR over the state-of-the-art Restormer on defocus / motion deblurring benchmark datasets with 32% fewer parameters and 39% fewer MACs. Extensive experiments demonstrate the superior performance of our network and the effectiveness of each module. Furthermore, we propose a compact and intuitive ERFMeter metric that quantitatively characterizes ERF, and shows a high correlation to the network performance. We hope this work can inspire the research community to further explore the pros and cons of CNN and Transformer architectures beyond image deblurring tasks.


SyncMos: Scalable Motion Synchronisation for Multi-Agent Scene Interaction
Lingxiao Li, Dongwon Kim, Lingyan Ruan, Bin Chen, Taesoo Kwon, Taehyun Rhee
IEEE/CVF CVPR 2026
ABSTRACT: Text-guided motion generation in 3D scenes has advanced the synthesis of human-scene interactions, contributing to embodied AI, scene understanding, and virtual agent simulation. While recent studies have begun exploring multi-agent scenarios, achieving temporally synchronised interactions among multiple agents remains an open challenge. Existing methods are often limited in flexibility and scalability when handling diverse interaction contexts.We present a method that enables synchronised multi-agent interaction using a single-agent motion synthesis model through two key components: a text-guided dependency-aware story planner and a temporal synchronisation module. The story planner interprets natural language instructions into structured event sequences with temporal dependencies. Our synchronisation module, built upon time-warping control and diffusion posterior sampling, aligns interaction timing across agents without retraining.Experimental results demonstrate that the proposed framework effectively models temporal dependencies and causal order between events. Evaluations across diverse interaction types show improved temporal alignment and coherent multi-agent motion generation consistent with textual instructions.


LFGAN: 4D Light Field Synthesis from a Single RGB Image
Bin Chen, Lingyan Ruan, Miuling Lam
Optics Express 2019
ABSTRACT: We present a deep neural network called the light field generative adversarial network (LFGAN) that synthesizes a 4D light field from a single 2D RGB image. We generate light fields using a single image super-resolution (SISR) technique based on two important observations. First, the small baseline gives rise to the high similarity between the full light field image and each sub-aperture view. Second, the occlusion edge at any spatial coordinate of a sub-aperture view has the same orientation as the occlusion edge at the corresponding angular patch, implying that the occlusion information in the angular domain can be inferred from the sub-aperture local information. We employ the Wasserstein GAN with gradient penalty (WGAN-GP) to learn the color and geometry information from the light field datasets. The network can generate a plausible 4D light field comprising 8×8 angular views from a single sub-aperture 2D image. We propose new loss terms, namely epipolar plane image (EPI) and brightness regularization (BRI) losses, as well as a novel multi-stage training framework to feed the loss terms at different time to generate superior light fields. The EPI loss can reinforce the network to learn the geometric features of the light fields, and the BRI loss can preserve the brightness consistency across different sub-aperture views. Two datasets have been used to evaluate our method: in addition to an existing light field dataset capturing scenes of flowers and plants, we have built a large dataset of toy animals consisting of 2,100 light fields captured with a plenoptic camera. We have performed comprehensive ablation studies to evaluate the effects of individual loss terms and the multi-stage training strategy, and have compared LFGAN to other state-of-the-art techniques. Qualitative and quantitative evaluation demonstrates that LFGAN can effectively estimate complex occlusions and geometry in challenging scenes, and outperform other existing techniques.
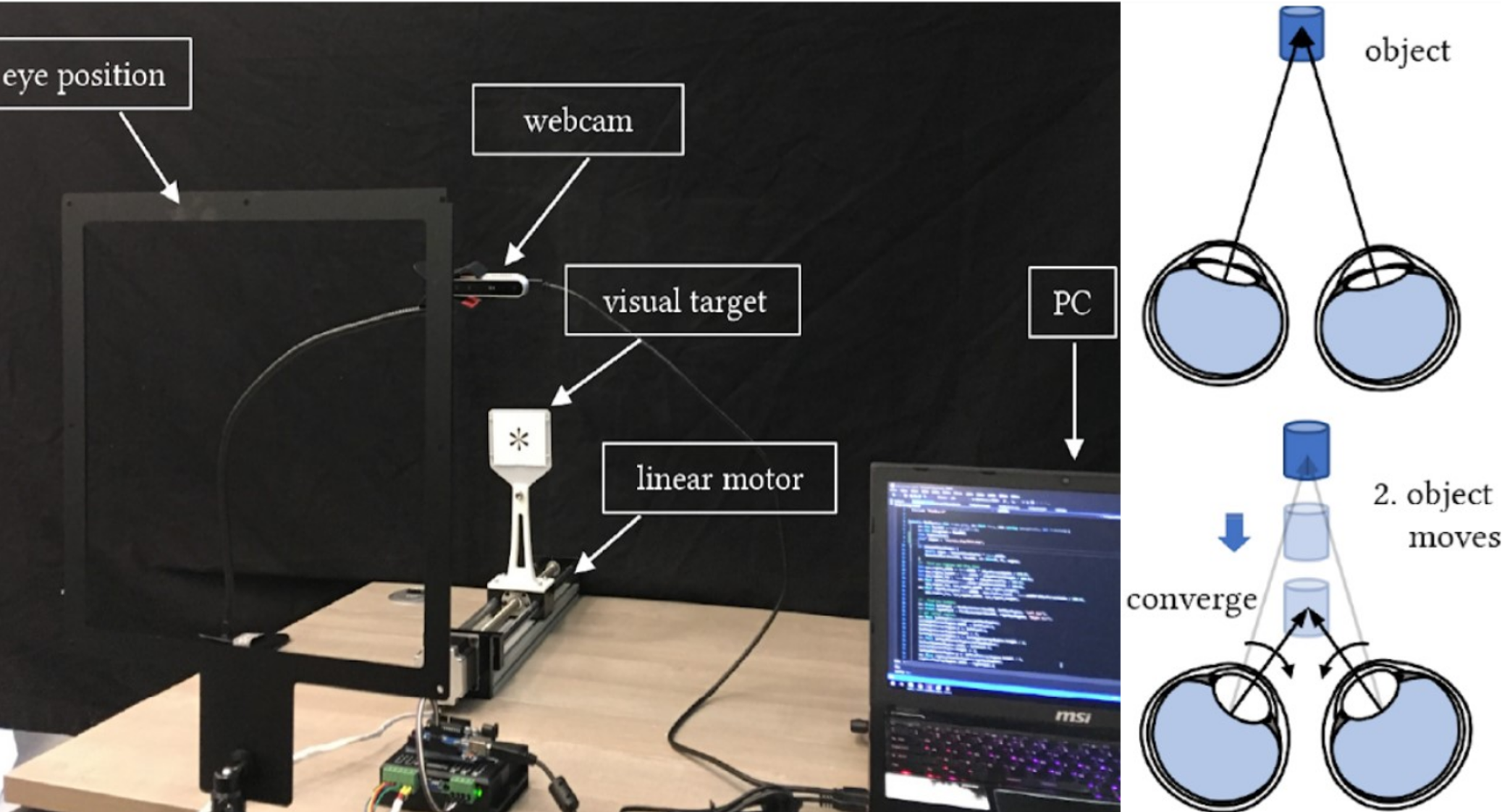
Human-Computer Interaction by Voluntary Vergence Control
Lingyan Ruan,Bin Chen, Miuling Lam
SIGGRAPH Asia Posters 2018
ABSTRACT: Most people can voluntarily control vergence eye movements. However, the interaction possibility of using vergence as an active input remain largely unexplored. We present a novel human-computer interaction technique which allows a user to control the depth position of an object based on voluntary vergence of the eyes. Our technique is similar to the mechanism for seeing the intended 3D image of an autostereogram, which requires cross-eyed or walleyed viewing. We invite the user to look at a visual target that is mounted on a linear motor, then consciously control the eye convergence to focus at a point in front of or behind the target. A camera is used to measure the eye convergence and control the motion of the linear motor dynamically based on the measured distance. Our technique can enhance existing eye-tracking methods by providing additional information in the depth dimension, and has great potential for hands-free interaction and assistive applications.
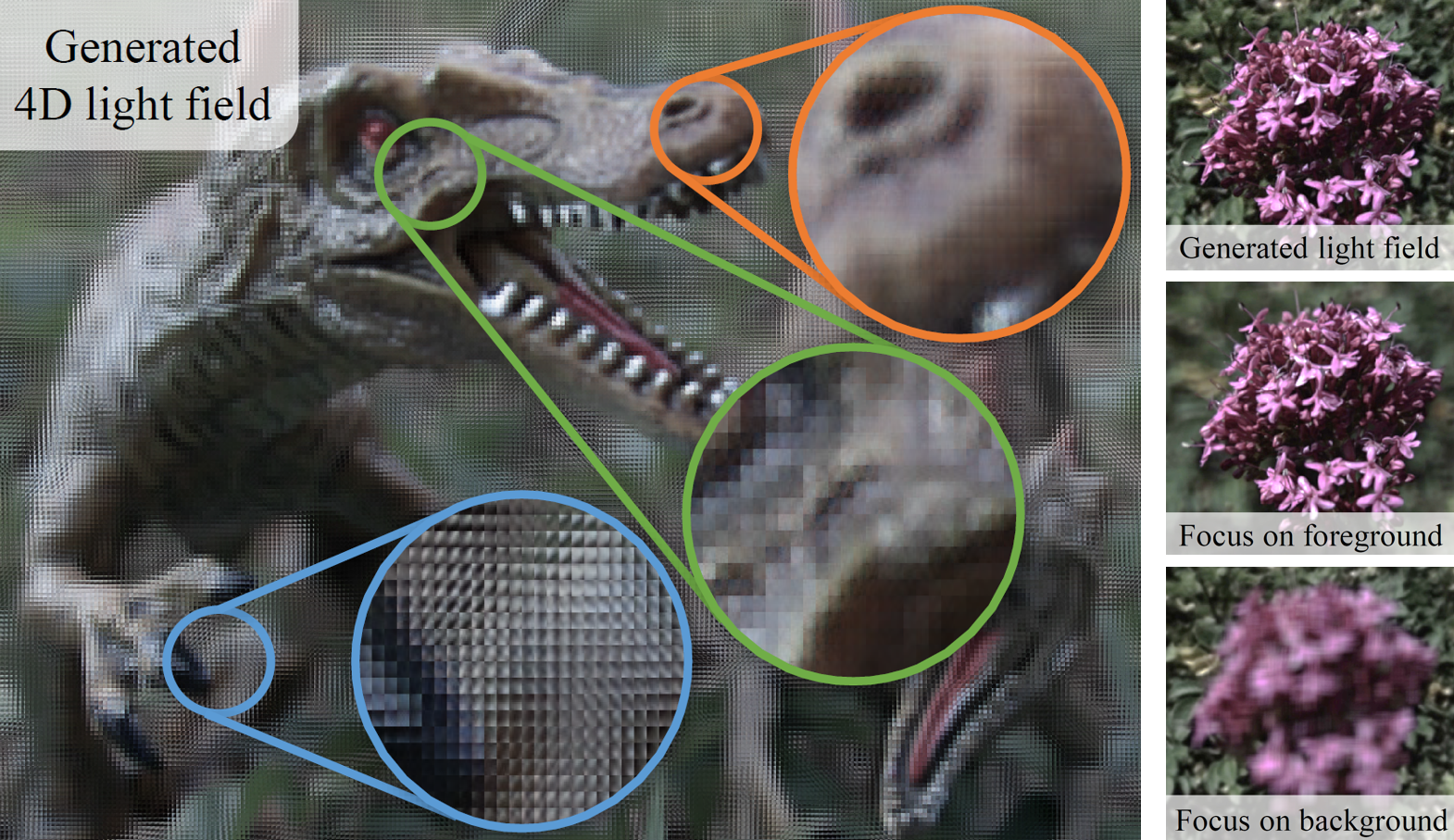
Light Field Synthesis from a Single Image using Improved Wasserstein Generative Adversarial Network
Lingyan Ruan,Bin Chen, Miuling Lam
Eurographics Posters 2018
ABSTRACT: Wepresent a deep learning-based method to synthesize a 4D light field from a single 2D RGB image. We consider the light field synthesis problem equivalent to image super-resolution, and solve it by using the improved Wasserstein Generative Adversarial Network with gradient penalty (WGAN-GP). Experimental results demonstrate that our algorithm can predict complex occlu sions and relative depths in challenging scenes. The light fields synthesized by our method has much higher signal-to-noise ratio and structural similarity than the state-of-the-art approach.